Professional Machine Learning Engineer
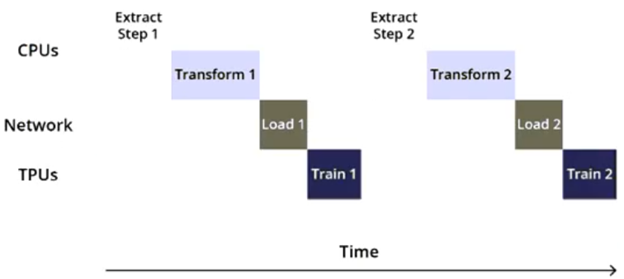
Cloud TPU v2を使用して物体検出モデルをトレーニングしています。トレーニング時間が予想よりも長くなっています。Cloud TPUプロファイルから取得したこの簡略化されたトレースに基づいて、コスト効率の良い方法でトレーニング時間を短縮するためにどのようなアクションを実行すべきですか?
データセットの探索的データ分析を行っている際に、ある重要なカテゴリ特徴量に5%の欠損値があることがわかりました。欠損値から生じる可能性のあるバイアスを最小限に抑えたいと考えています。これらの欠損値にどのように対処すべきですか?
あなたは農業研究チームのMLエンジニアで、作物の画像から葉のさび病の斑点を検出し、病気の存在を判断するための作物病害検出ツールに取り組んでいます。これらの斑点は、形状や大きさが様々であり、病気の重症度と相関しています。あなたは、病気の存在と重症度を高精度で予測するソリューションを開発したいと考えています。どうすべきでしょうか?
あなたは、Kerasを使用して構築された概念実証(PoC)のMLモデルを本番環境に移行するよう依頼されました。このモデルは、データサイエンティストのローカルマシン上のJupyter Notebookでトレーニングされました。Notebookには、データ検証を実行するセルとモデル分析を実行するセルが含まれています。あなたは、Notebookに含まれるステップをオーケストレーションし、毎週の再トレーニングのためにこれらのステップの実行を自動化する必要があります。将来的には、トレーニングデータが大幅に増加すると予想されます。あなたは、コストを最小限に抑えながら、マネージドサービスを活用するソリューションを望んでいます。どうすべきでしょうか?
あなたはGoogle Cloud上で深層ニューラルネットワークモデルを訓練しました。このモデルは訓練データでの損失は低いものの、検証データでの性能は劣っています。モデルが過学習に対して頑健になるようにしたいと考えています。モデルを再訓練する際に、どの戦略を使用すべきですか?