Professional Machine Learning Engineer
あなたはeコマース企業のMLエンジニアで、物流チームが毎月注文すべき在庫量を予測するモデルの構築を任されました。どのアプローチを取るべきですか?
あなたは、世界中の消費者支出がインフレに与える影響を予測するTensorFlowモデルを金融機関向けに構築しています。データのサイズと性質上、モデルはあらゆる種類のハードウェアで長時間実行され、トレーニングプロセスには頻繁なチェックポイント作成を組み込んでいます。あなたの組織はコストを最小限に抑えるよう求めています。どのハードウェアを選択すべきですか?
あなたは、ソーシャルメディアプラットフォーム上のスパム投稿にフラグを立てて非表示にするスパム対策サービスを提供する会社に勤務しています。あなたの会社は現在、20万語のキーワードリストを使用して、疑わしいスパム投稿を特定しています。投稿にこれらのキーワードがいくつか以上含まれている場合、その投稿はスパムとして識別されます。あなたは、人間によるレビューのためにスパム投稿にフラグを立てるために機械学習の使用を開始したいと考えています。このビジネスケースで機械学習を導入する主な利点は何ですか?
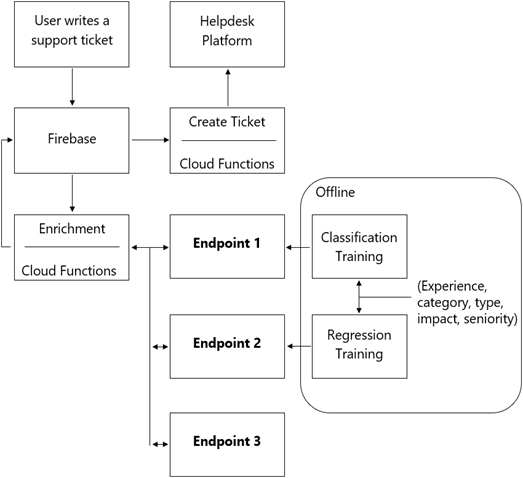
あなたは、カスタマーサポートのチケットがサポート担当者にルーティングされる前に、有益なメタデータで補強するためのサーバーレスMLシステムを備えたアーキテクチャを設計しています。チケットの優先度を予測し、チケットの解決時間を予測し、感情分析を実行する一連のモデルが必要です。これにより、担当者がサポートリクエストを処理する際に戦略的な意思決定を行えるようになります。チケットには、ドメイン固有の用語や専門用語は含まれていないと想定されています。 提案されているアーキテクチャには、以下のフローがあります。 Enrichment Cloud Functionsはどのエンドポイントを呼び出すべきですか?
あなたのモデルの一つは、サードパーティのデータブローカーから提供されたデータを使用して学習されています。そのデータブローカーは、データのフォーマット変更について、あなたに確実に通知してくれるわけではありません。あなたは、このような問題に対して、モデルの学習パイプラインをより堅牢にしたいと考えています。どうすればよいでしょうか?