Professional Machine Learning Engineer
あなたは最近、表形式データでXGBoostモデルをトレーニングしました。このモデルをHTTPマイクロサービスとして社内利用に公開する予定です。デプロイ後、受信リクエスト数は少ないと予想されます。最小限の労力とレイテンシでモデルを本番環境に移行したいと考えています。どうすべきでしょうか?
あなたは、科学製品を世界中に出荷する国際的な製造組織に勤務しています。これらの製品の取扱説明書は、15の異なる言語に翻訳する必要があります。組織のリーダーシップチームは、手作業による翻訳コストを削減し、翻訳速度を向上させるために、機械学習の利用を開始したいと考えています。あなたは、精度を最大化し、運用オーバーヘッドを最小限に抑えるスケーラブルなソリューションを実装する必要があります。また、誤訳を評価し修正するプロセスも組み込みたいと考えています。どうすべきでしょうか?
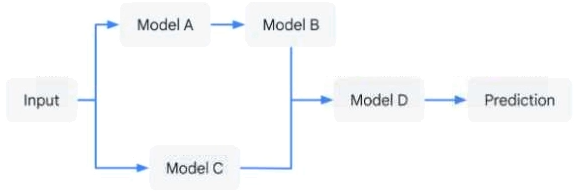
あなたは、複数のscikit-learnモデルの連鎖を使用して、自社製品の最適価格を予測するアプリケーションを開発しました。ワークフローロジックは図に示されています。チームのメンバーは、個々のモデルを他のソリューションワークフローでも使用します。各個別モデルとワークフロー全体のバージョン管理を保証しながら、このワークフローをデプロイしたいと考えています。アプリケーションはゼロにスケールダウンできる必要があります。このソリューションの管理に必要なコンピューティングリソースの使用量と手動作業を最小限に抑えたいと考えています。どうすべきですか?
あなたは、さまざまなオンプレミスのデータマートにまたがる統合分析環境の構築を担当しています。あなたの会社では、多種多様な分断されたツールや一時的なソリューションを使用していることが原因で、サーバー間でデータを統合する際にデータ品質とセキュリティの課題が発生しています。作業の総コストを削減し、反復作業を減らすことができる、フルマネージドのクラウドネイティブなデータ統合サービスが必要です。チームの一部のメンバーは、ETL(抽出、変換、ロード)プロセスを構築するためのコードレスインターフェースを好んでいます。どのサービスを使用すべきですか?
あなたは、重要な機械部品で故障が発生するかどうかを予測するモデルを開発しています。多変量時系列と、機械部品が故障したかどうかを示すラベルで構成されるデータセットがあります。最近、Vertex AI Workbenchノートブックで、いくつかの異なる前処理およびモデリングアプローチの実験を開始しました。各実行からデータとアーティファクトをログに記録し、追跡したいと考えています。どのように実験をセットアップすべきですか?