Professional Machine Learning Engineer
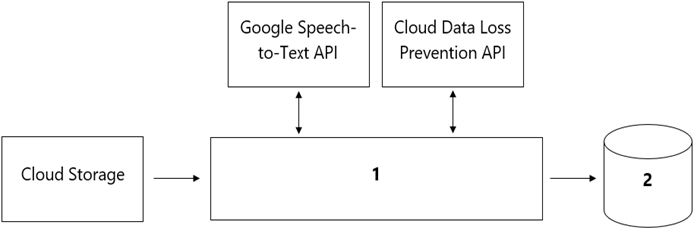
あなたの組織のコールセンターから、各通話における顧客の感情を分析するモデルの開発を依頼されました。コールセンターは毎日100万件以上の通話を受信し、データはCloud Storageに保存されています。収集されたデータは発信元のリージョン外に持ち出すことはできず、個人を特定できる情報(PII)を保存または分析することもできません。データサイエンスチームは、SQL ANSI-2011準拠のインターフェースを必要とするサードパーティ製の可視化およびアクセス用ツールを使用しています。データ処理と分析のためのコンポーネントを選択する必要があります。データパイプラインはどのように設計すべきですか?
あなたは、複数のGoogle Cloudプロジェクトにまたがるデータを使用して、Vertex AIでモデルをトレーニングしています。モデルの異なるバージョンのパフォーマンスを検索、追跡、比較する必要があります。MLワークフローに含めるべきGoogle Cloudサービスはどれですか?
あなたはKerasとTensorFlowを使用して不正検知モデルを開発しています。顧客の取引記録はBigQueryの大規模なテーブルに保存されています。モデルの訓練に使用する前に、これらの記録をコスト効率よく効率的な方法で前処理する必要があります。訓練されたモデルは、BigQueryでバッチ推論を実行するために使用されます。前処理ワークフローはどのように実装すべきですか?
TensorFlowを使用して画像分類モデルを学習する必要があります。あなたのデータセットはCloud Storageディレクトリにあり、数百万のラベル付き画像が含まれています。モデルを学習する前に、データを準備する必要があります。データの前処理とモデル学習のワークフローを、可能な限り効率的で、スケーラブル、かつ低メンテナンスにしたいと考えています。どうすべきでしょうか?
あなたはカスタム画像分類モデルを構築しており、Vertex AI Pipelines を使用してエンドツーエンドのトレーニングを実装する予定です。あなたのデータセットは画像で構成されており、モデルのトレーニングに使用する前に前処理を行う必要があります。前処理ステップには、画像のリサイズ、グレースケールへの変換、特徴量の抽出が含まれます。あなたは既に前処理タスクのためのいくつかのPython関数を実装しています。パイプラインではどのコンポーネントを使用すべきですか?