Professional Machine Learning Engineer
あなたは、テキストベースの製品レビューから感情スコアを予測するためのモデル訓練パイプラインを作成しています。モデルパラメータの調整方法を制御できるようにしたいと考えており、訓練後にモデルをエンドポイントにデプロイする予定です。パイプラインの実行にはVertex AI Pipelinesを使用します。どのGoogle Cloudパイプラインコンポーネントを使用するかを決定する必要があります。どのコンポーネントを選択すべきですか?
あなたのチームは、頻繁に新しい機械学習(ML)モデルを作成し、実験を実行しています。チームは、Cloud Source Repositories でホストされている単一のリポジトリにコードをプッシュしています。コードに何らかの変更があるたびにモデルを自動的に再トレーニングする継続的インテグレーション(CI)パイプラインを作成したいと考えています。CIパイプラインを設定するための最初のステップは何でしょうか?
予測を行う前にメモリを大量に消費するいくつかの前処理タスクを実行するカスタムモデルを構築しました。このモデルをVertex AIエンドポイントにデプロイし、結果が妥当な時間内に受信されることを検証しました。その後、ユーザートラフィックをエンドポイントにルーティングしたところ、複数のリクエストを受信した際にエンドポイントが期待通りにオートスケールしないことが判明しました。どうすべきでしょうか?
あなたの会社はeコマースウェブサイトを管理しています。あなたは、ユーザーのカートに現在入っている商品に基づいて、ほぼリアルタイムで追加の商品をユーザーに推奨するMLモデルを開発しました。ワークフローには以下のプロセスが含まれます: 1. ウェブサイトは関連データを含むPub/Subメッセージを送信し、その後Pub/Subから予測結果を含むメッセージを受信します。 2. 予測結果はBigQueryに保存されます。 3. モデルはCloud Storageバケットに保存され、頻繁に更新されます。 あなたは予測レイテンシとモデル更新に必要な手間を最小限に抑えたいと考えています。アーキテクチャをどのように再構成すべきですか?
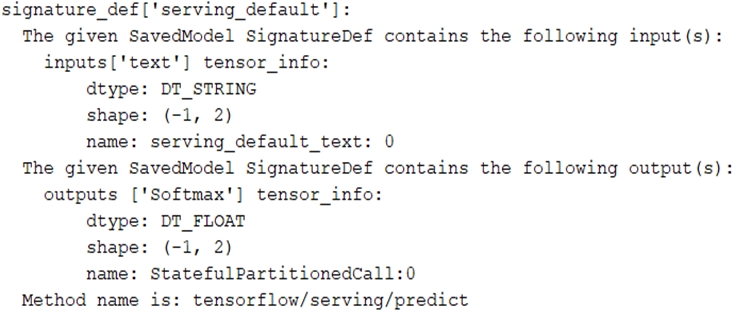
テキスト分類モデルを訓練しました。次のSignatureDefsがあります。 TensorFlow-servingコンポーネントサーバーを起動し、次のHTTPリクエストを送信して予測を取得しようとしました: headers = {'content-type': 'application/json'} json_response = requests.post('http: //localhost:8501/v1/models/text_model:predict', data=data, headers=headers) 予測リクエストを作成する正しい方法は何ですか?