Professional Cloud Architect
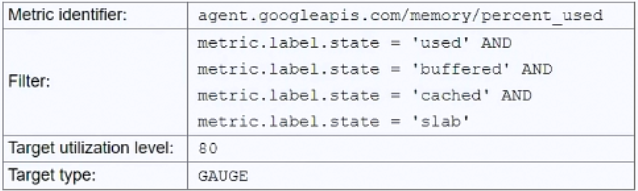
Compute Engine アプリケーションがあり、合計メモリ使用量が 80% を超えたときに自動スケーリングさせたいと考えています。Cloud Monitoring エージェントをインストールし、自動スケーリング ポリシーを次のように構成しました: 高負荷時にアプリケーションがスケーリングしないことがわかりました。これを解決したいと考えています。どうすればよいですか?
あなたの会社では、数ペタバイトのデータセットをクラウドに移行する計画があります。データセットは24時間利用可能である必要があります。ビジネスアナリストはSQLインターフェースの使用経験しかありません。 分析の容易さを最適化するために、データをどのように保存すべきですか?
正確なリアルタイムの気象チャートアプリケーションのパフォーマンスを最適化したいと考えています。データは50,000個のセンサーから1秒あたり10回の読み取り値が、タイムスタンプとセンサー読み取り値の形式で送信されます。 このデータはどこに保存すべきですか?
あなたの会社は、データウェアハウジングにBigQueryを使用するGoogle Cloudプロジェクトを持っています。オンプレミス環境とGoogle Cloud間のVPNトンネルはCloud VPNで構成されています。セキュリティチームは、悪意のある内部関係者、侵害されたコード、偶発的な過剰共有によるデータ漏洩を回避したいと考えています。あなたは何をすべきですか?
あなたの会社のユーザーフィードバックポータルは、2つのゾーンに複製された標準的なLAMPスタックで構成されています。これはus-central1リージョンにデプロイされており、データベースを除くすべてのレイヤーで自動スケーリングされるマネージドインスタンスグループを使用しています。現在、選ばれた少数の顧客グループのみがポータルにアクセスできます。これらの条件下で、ポータルは99.99%の可用性SLAを満たしています。しかし、来四半期には、あなたの会社は認証されていないユーザーを含むすべてのユーザーがポータルを利用できるようにします。追加のユーザー負荷が導入された後もシステムがSLAを維持できるように、回復性テスト戦略を開発する必要があります。 何をすべきですか?